Every system administrator has to deal with plain text files on a daily basis. Knowing how to view certain sections, how to replace words, and how to filter content from those files are skills you need to have handy without having to do a Google search.
In this article we will review sed, the well-known stream editor, and share 15 tips to use it in order to accomplish the goals mentioned earlier, and more.
What is Sed Command?
The ‘sed‘ command, short for stream editor, is a versatile and powerful text manipulation tool that operates on text streams, allowing users to perform various operations on data, such as search, replace, insert, and delete. ‘Sed’ uses regular expressions to define patterns for text manipulation, and it can be employed for batch editing tasks and text processing in scripts.
One of its notable features is in-place editing, where it can modify files directly or create backup copies while making changes. ‘Sed‘ is an essential tool for system administrators, programmers, and anyone dealing with text transformation and data manipulation tasks in the command line.
Following are some common ‘sed‘ commands with examples:
1. Viewing a Range of Lines of a File
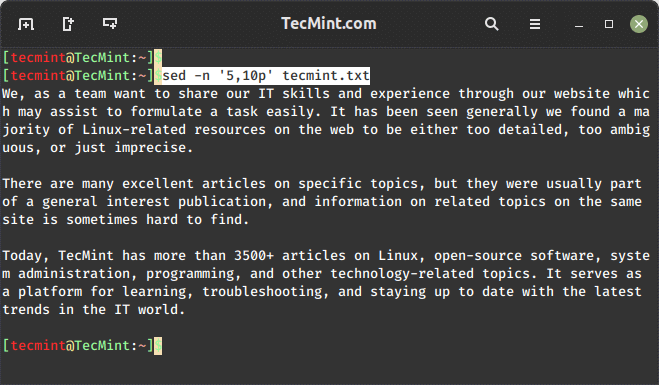
Tools such as head and tail allow us to view the bottom or the top of a file. What if we need to view a section in the middle? The following sed one-liner will return lines 5 through 10 from tecmint.txt:
sed -n '5,10p' tecmint.txt
2. Viewing the Entire File Except a Given Range
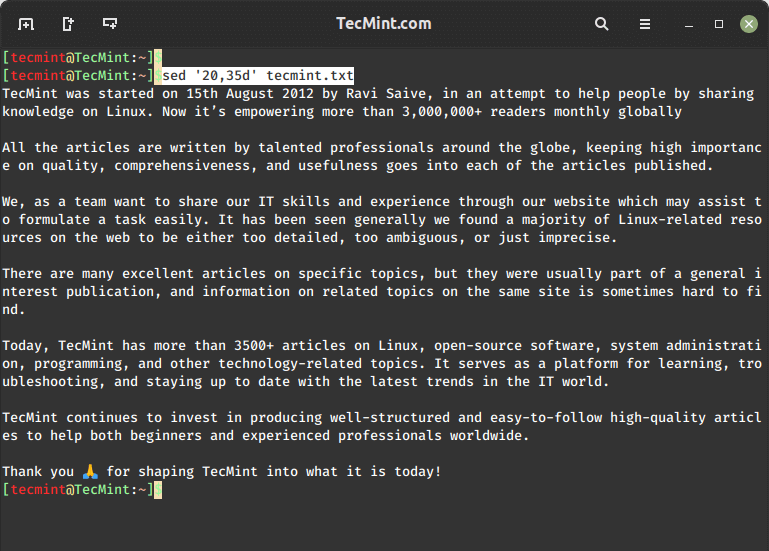
On the other hand, it’s possible that you want to print the entire file except a certain range. To exclude lines 20 through 35 from tecmint.txt, do:
sed '20,35d' myfile.txt
3. Viewing Non-Consecutive Lines and Ranges
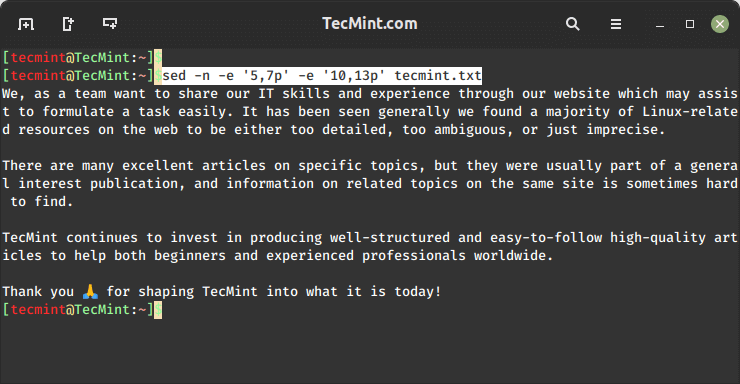
It’s possible that you’re interested in a set of non-consecutive lines, or in more than one range. Let’s display lines 5-7 and 10-13 from tecmint.txt:
sed -n -e '5,7p' -e '10,13p' tecmint.txt
As you can see, the -e option allows us to execute a given action (in this case, print lines) for each range.
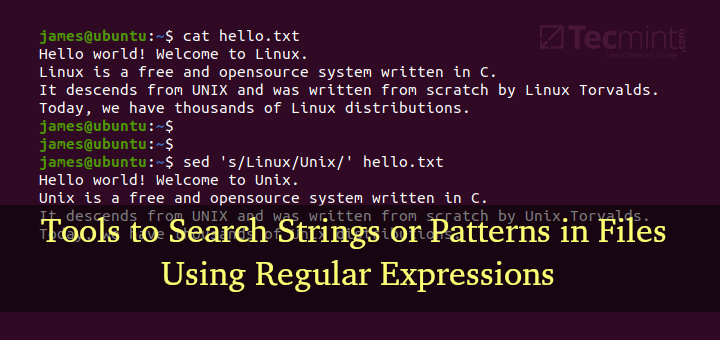
4. Replacing Words or Strings in a File
To replace every instance of the word version with story in tecmint.txt, do:
sed 's/version/story/g' tecmint.txt
Additionally, you may want to consider using gi instead of g in order to ignore character case:
sed 's/version/story/gi' myfile.txt
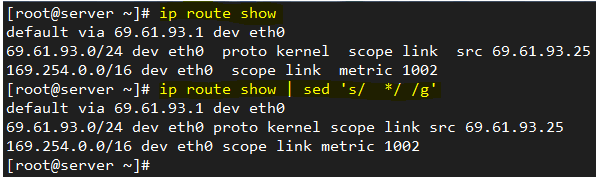
To replace multiple blank spaces with a single space, we will use the output of the command ip route show with a pipeline:
ip route show | sed 's/ */ /g'
Compare the output of ip route show with and without the pipeline:
5. Replacing Words or Strings Inside a Range
If you’re interested in replacing words only within a line range (30 through 40, for example), you can do:
sed '30,40 s/version/story/g' tecmint.txt
Of course, you can indicate a single line through its corresponding number instead of a range.
6. Remove Comments From a File
Sometimes configuration files are loaded with comments. While this is certainly useful, it may be helpful to display only the configuration directives sometimes if you want to view them all at a glance.
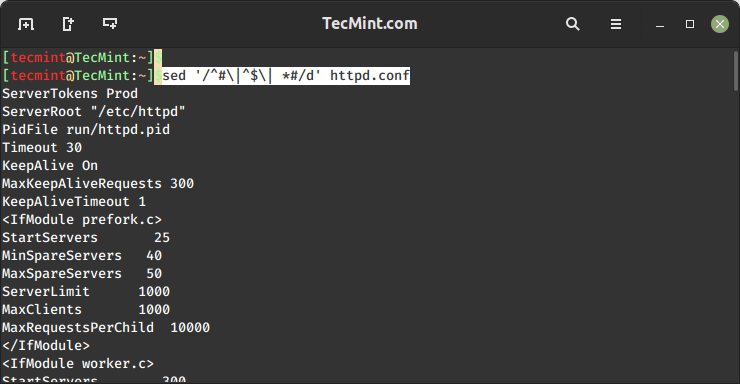
To remove empty lines or those beginning with # from the Apache configuration file, do:
sed '/^#\|^$\| *#/d' httpd.conf
The caret sign is followed by the number sign (^#) indicates the beginning of a line, whereas ^$ represents blank lines. The vertical bars indicate boolean operations, whereas the backward slash is used to escape the vertical bars.
In this particular case, the Apache configuration file has lines with #’s not at the beginning of some lines, so *# is used to remove those as well.
7. Replace a Case-insensitive Word in a File
To replace a word beginning with uppercase or lowercase with another word, we can also use sed. To illustrate, let’s replace the word zip or Zip with rar in tecmint.txt:
sed 's/[Zz]ip/rar/g' tecmint.txt
8. Finding a Specific Events in a Log File
Another use of sed consists in printing the lines from a file that match a given regular expression. For example, we may be interested in viewing the authorization and authentication activities that took place on July 2, as per the /var/log/secure log in a CentOS server.
In this case, the pattern to search for is Jul 2 at the beginning of each line:
sed -n '/^Jul 1/ p' /var/log/secure

9. Inserting Spaces or Blank Lines in a File
With sed, we can also insert spaces (blank lines) for each non-empty line in a file. To insert one blank line every other line in LICENSE, a plain text file, do:
sed G tecmint.txt
To insert two blank lines, do:
sed 'G;G' tecmint.txt
Add an uppercase G separated by a semicolon if you want to add more blank lines. The following image illustrates the example outlined in this tip:
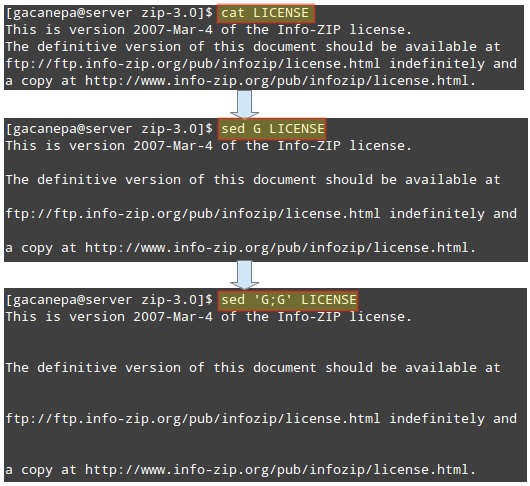
This tip may come in handy if you want to inspect a large configuration file. Inserting a blank space every other line and piping the output to less will result in a more-friendly reading experience.
10. Removing ^M in a File
The dos2unix program converts plain text files from Windows/Mac formatting to Unix/Linux, removing hidden newline characters inserted by some text editors used in those platforms. If it is not installed in your Linux system, you can mimic its functionality with sed instead of installing it.
In the image at the left we can see several DOS newline characters (^M), which were later removed with:
sed -i 's/\r//' myfile.txt
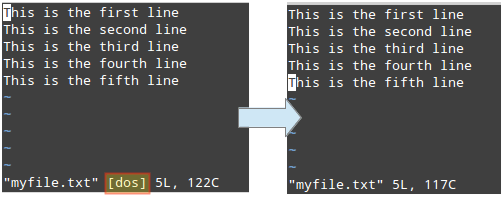
Please note that the -i option indicates in-place editing. Then changes will not be returned to the screen but will be saved to the file.
Note: You can insert DOS newline characters while editing a file in Vim editor with Ctrl+V and Ctrl+M.
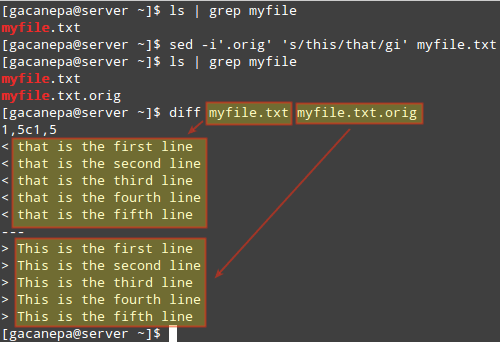
11. Create a Backup File with Sed Command
In the previous tip, we used sed to modify a file but did not save the original file. Sometimes it’s a good idea to save a backup copy of the original file just in case.
To do that, indicate a suffix following the -i option (inside single quotes) to be used to rename the original file.
In the following example, we will replace all instances of this or This (ignoring case) with that in myfile.txt, and we will save the original file as myfile.txt.orig.
Finally, we will use diff utility to identify the differences between both files:
sed -i'.orig' 's/this/that/gi' myfile.txt
12. Switching Pairs of Words in a File
Let’s suppose you have a file containing full names in the format First name, Last name. To adequately process the file, you may want to switch Last name and First name.
We can do that with sed fairly easily:
sed 's/^\(.*\),\(.*\)$/\2\, /g' names.txt
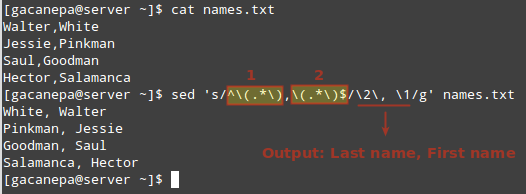
In the image above we can see that parentheses, being special characters, need to be escaped, as do the numbers 1 and 2.
These numbers represent the highlighted regular expressions (which need to appear inside parentheses):
- 1 represents the beginning of each line up to the comma.
- 2 is a placeholder for everything that is right of the comma to the end of the line.
The desired output is indicated in the format SecondColumn (Last name) + comma + space + FirstColumn (First name). Feel free to change it to whatever you wish.
13. Replacing Words Only if a Separate Match is Found
Sometimes replacing all instances of a given word, or a random few, is not precisely what we need. Perhaps we need to perform the replacement if a separate match is found.
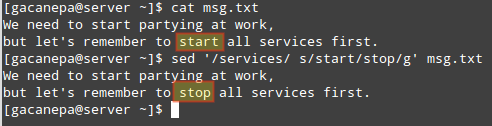
For example, we may want to replace start with stop only if the word services is found in the same line. In that scenario, here’s what will happen:
We need to start partying at work, but let’s remember to start all services first.
In the first line, start will not be replaced with stop since the word services do not appear in that line, as opposed to the second line.
# sed '/services/ s/start/stop/g' msg.txt
14. Performing Two or More Substitutions at Once
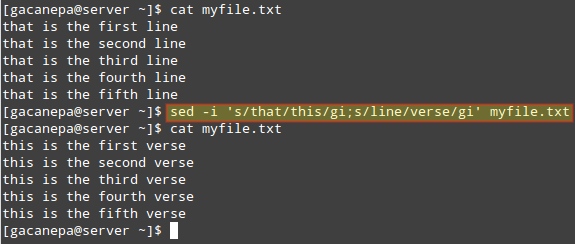
You can combine two or more substitutions in one single sed command. Let’s replace the words that and line in myfile.txt with This and verse, respectively.
Note how this can be done by using an ordinary sed substitution command followed by a semicolon and a second substitution command:
# sed -i 's/that/this/gi;s/line/verse/gi' myfile.txt
This tip is illustrated in the following image:
15. Combining Sed and Other Commands
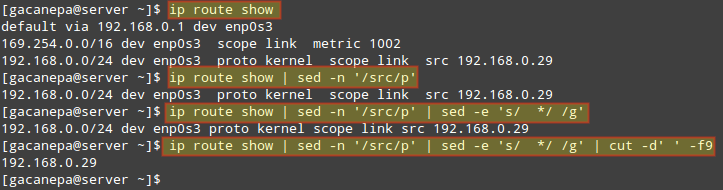
Of course, sed can be combined with other Linux commands in order to create more powerful commands. For example, let’s use the example given in TIP #4 and extract our IP address from the output of the ip route command.
We will begin by printing only the line where the word src is. Then we will convert multiple spaces into a single one. Finally, we will cut the 9th field (considering a single space as a field separator), which is where the IP address is:
# ip route show | sed -n '/src/p' | sed -e 's/ */ /g' | cut -d' ' -f9
The image below illustrates each step of the above command:
Summary
In this guide, we have shared 15 sed tips and tricks to help you with your daily system administration tasks. Is there any other tip that you use on a regular basis and would like to share with us and the rest of the community?
If so, feel free to let us know using the comment form below. Questions and comments are also welcome – we look forward to hearing from you!

Hello,
Please look at tip no. 12. (Switching pairs of words) and compare a command used in an example – there are not the same.
Despite that, the tutorial is very useful. Thanks for your effort.
This is very good and useful.
No collection of sed tips is complete without a reference to the famous sed 1 liners
http://sed.sourceforge.net/sed1line.txt
Hey,
I got a question here. Is there a option to roll back to original content once after using sed command to replace any?
Kingstan.
thanks, helpful article
Even though I have used regex a few times, I keep finding it difficult to create them, thank you for this excellent tips.
@Mauricio,
I am glad that you found these tips useful. Please help us spread the word by sharing this article in your social network profiles!
thanks , powerful article .
@yashar,
Thank you for taking the time to comment! Please helps us to spread the word by sharing this article through your social media profiles! :)